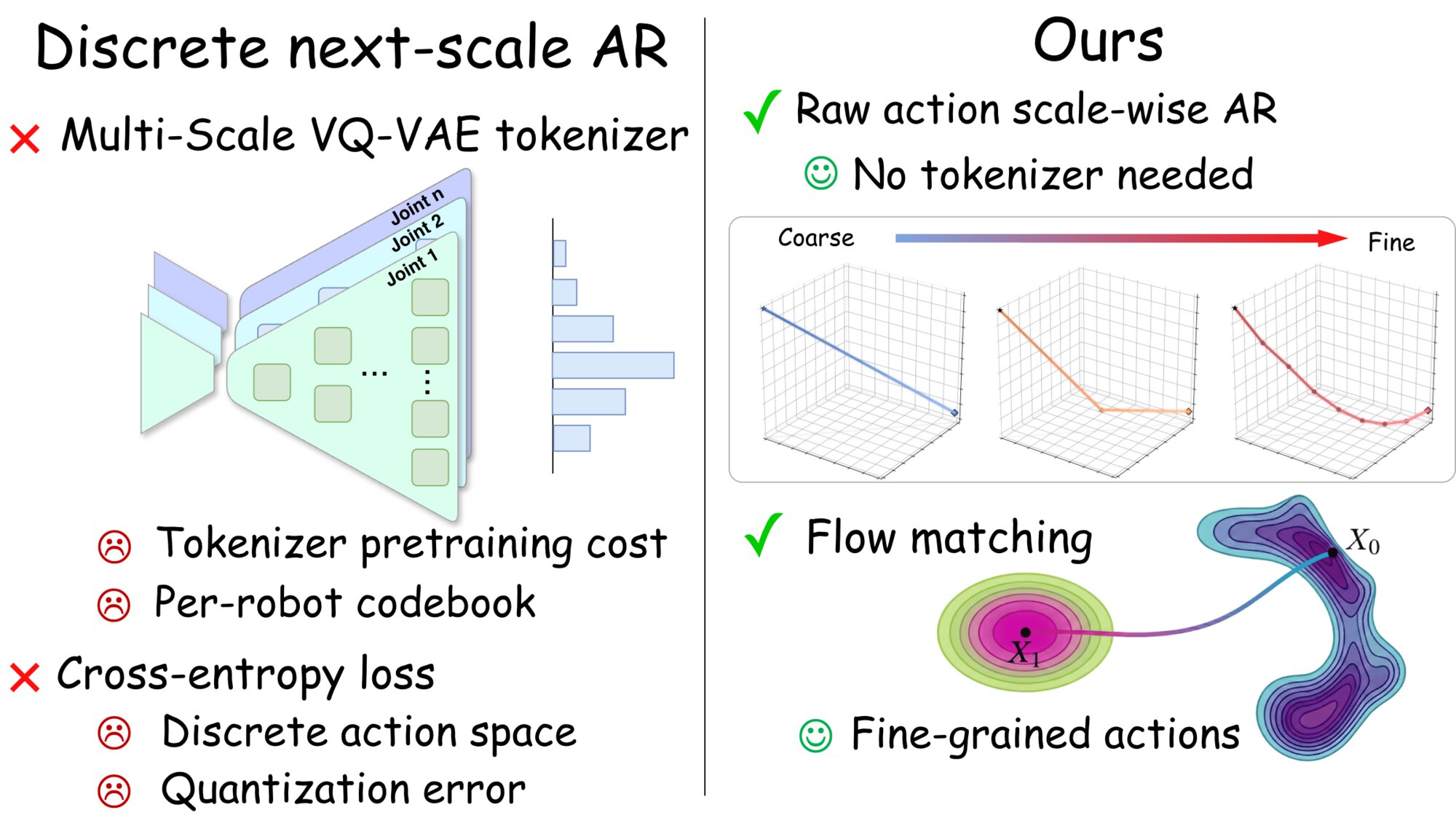
Coarse-to-fine autoregressive modeling has recently shown strong promise for visuomotor policy learning, combining the inference efficiency of autoregressive methods with the global trajectory coherence of diffusion-based policies. However, existing approaches rely on discrete action tokenizers that map continuous action sequences to codebook indices, a design inherited from image generation where learned compression is necessary for high-dimensional pixel data. We observe that robot actions are inherently low-dimensional continuous vectors, for which such tokenization introduces unnecessary quantization error and a multi-stage training pipeline. In this work, we propose Hierarchical Flow Policy (HiFlow), a tokenization-free coarse-to-fine autoregressive policy that operates directly on raw continuous actions. HiFlow constructs multi-scale continuous action targets from each action chunk via simple temporal pooling, averaging contiguous action windows to produce coarse summaries that are refined at finer temporal resolutions. The entire model is trained end-to-end in a single stage, eliminating the need for a separate tokenizer. Experiments on MimicGen, RoboTwin 2.0, and real-world environments demonstrate that HiFlow consistently outperforms existing methods including diffusion-based and tokenization-based autoregressive policies.
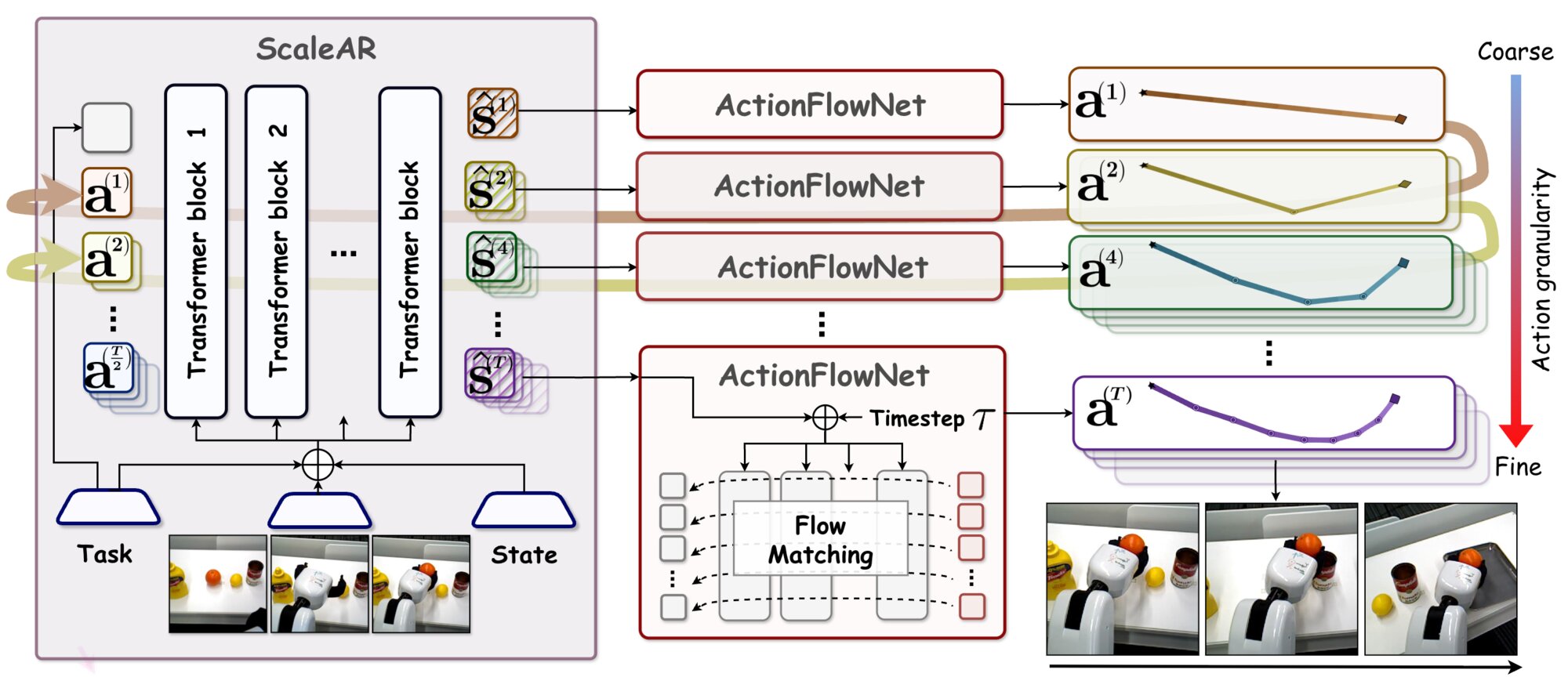
Given visual observations, proprioceptive states, and a task identifier, the scale-wise autoregressive Transformer (ScaleAR) produces conditioning features at progressively finer temporal scales via a scale-wise causal mask. A shared ActionFlowNet then generates continuous actions at each scale through conditional flow matching, progressively refining the trajectory from a single-token global summary to the full action chunk. The entire pipeline operates in continuous action space without any discrete tokenization.

We evaluate on three benchmarks: MimicGen (8 single-arm manipulation tasks), RoboTwin 2.0 (3 dual-arm tasks), and real-world experiments (5 tasks with a mobile manipulator spanning object grasping, relocation, and target placement).

Successful rollouts on representative tasks: (a) Threading from MimicGen, where HiFlow generates smooth trajectories for precise needle insertion; (b) Place can basket from RoboTwin 2.0, demonstrating coordinated bimanual manipulation.

Real-world Orange→Plate task: HiFlow reliably grasps the orange and places it at the target location, producing smooth and consistent trajectories without abrupt corrections under real-world sensory noise.
Apple
Coke
Mustard
Orange
Tennis Ball
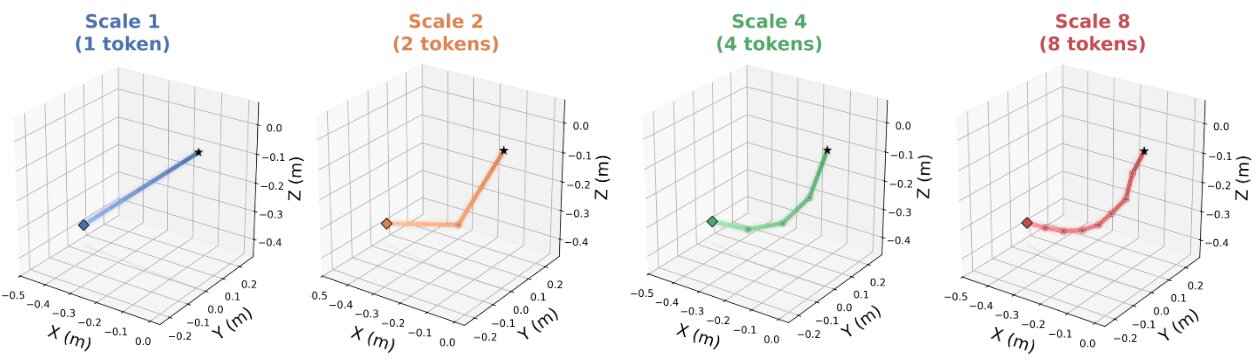
Visualization of scale-wise trajectory refinement. At Scale 1, a single token captures the overall direction. As the scale increases, additional tokens progressively refine the trajectory with finer temporal detail and curvature, confirming the coarse-to-fine generation process.
@inproceedings{yashima2026hiflow,
title = {HiFlow: Tokenization-Free Scale-Wise Autoregressive Policy Learning via Flow Matching},
author = {Yashima, Daichi and Seno, Koki and Kurita, Shuhei and Oda, Yusuke and Sugiura, Komei},
booktitle = {IEEE/RSJ IROS},
year = {2026}
}